
[ELK] LogStash(로그스태시)란?
업데이트:
✅ LogStash(로그스태시)란?
LogStash는 실시간 파이프라인 기능을 갖춘 오픈 소스 데이터 수집 엔진이다. LogStash는 서로 다른 소스의 데이터를 동적으로 통합하고 해당 데이터를 원하는 대상으로 정규화할 수 있다.
LogStash는 원래 로그 수집을 위한 목적으로 사용됐지만, 현재는 로그 수집을 넘어서 훨씬 많은 기능을 위해 사용된다. 다양한 범위의 input, output, filter를 통해 많은 유형의 이벤트를 변환 할 수 있으며, 데이터 수집 프로세스를 단순화 한다.

✅ LogStash의 동작 방식
LogStash 이벤트 처리 파이프라인은 inputs -> filters -> outputs의 세 단계로 구성된다. Inputs은 이벤트를 생성하고, Filters는 이벤트를 수정하며, Outputs은 이벤트를 다른곳으로 전달한다. LogStash의 입출력은 데이터가 파이프라인에 들어오거나 나갈 때 데이터를 인코딩/디코딩 할 수 있는 코덱을 지원한다.
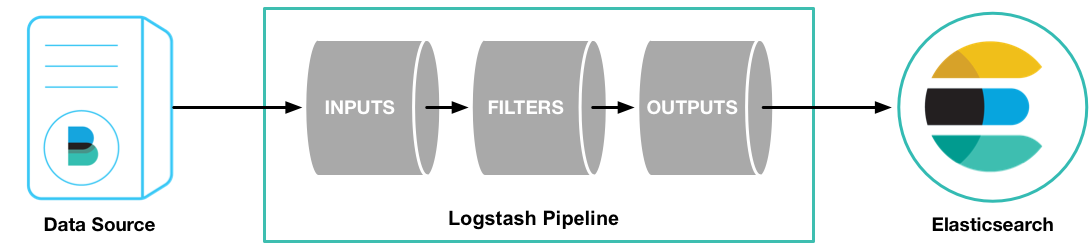
📌 Inputs ( 입력 )
데이터는 여러시스템에 다양한 형태로 보관된 경우가 많은데, LogStash는 다양한 소스에서 이벤트를 동시에 가져오는 input 플러그인을 광범위하게 지원한다. 로그, 메트릭, 웹, DB저장소, AWS 등에서 데이터를 수집할 수 있다.

- file : UNIX명령어인
tail -0F처럼 파일시스템에서 파일을 읽어온다. - syslog : 514포트를 통해 syslog 메시지를 읽어오고 RFC3164 포맷에 따라 구분한다.
- redis : redis 채널과 redis 목록을 모두 사용하여 redis 서버로부터 읽어온다.
-
beats : Beats에서 보낸 이벤트를 처리한다.
- jdbc : JDBC 데이터를 통해 이벤트를 생성한다.
LogStash의 Input 플러그인은 이외에도 굉장히 많고 필요에 따라 골라서 사용하면 된다.
📌 Filters ( 필터 )
필터는 LogStash 파이프라인의 중간 처리 장치이다. 필터를 조건과 결합하여 특정 기준을 충족하는 경우 이벤트에 대한 작업을 수행할 수 있다. 데이터가 소스에서 저장소로 이동하는 과정에서 각 이벤트를 구문 분석하고 명명된 필드를 식별하여 구조를 구축하며, 이를 공통 형식으로 변환 통합하여 분석한다. 자주 쓰이는 필터는 다음과 같다.

- grok : 임의의 텍스트를 분석하고 구조화한다. 현재 LogStash에서 구조화되지 않은 로그데이터를 구조화하고 구문 분석하는 가장 좋은 방법이다.
filter {
grok {
match => { "message" =>
"%{IP:client} %{WORD:method} %{URIPATHPARAM:request}
%{NUMBER:바이트} %{NUMBER:기간}"
}
}
}
- mutate : 이벤트의 필드 이름 변경, 제거, 수정 등의 변환을 수행한다.
filter {
mutate {
split => ["hostname", "."]
add_field => { "shortHostname" => "%{hostname[0]}" }
}
mutate {
rename => ["shortHostname", "hostname" ]
}
}
이 구성은 원래의 hostname 필드를 점(.)으로 구분하여 분할한 후 첫 번째 부분을 shortHostname 필드에 추가하고, 마지막으로 shortHostname 필드의 이름을 다시 hostname으로 변경한다. 이렇게 함으로써, 예를 들어 example.com에서 example만 추출하여 hostname 필드에 저장하는 것과 같은 작업을 수행한다.
filter {
mutate {
remove_field => ['@version','es_contents','@timestamp']
add_field => {
"pk" => "%{kedcd}"
}
}
}
위 코드는 @version,es_contents',@timestamp라는 필드를 삭제하고, pk라는 필드를 추가하며 pk필드의 값으로는 kedcd 필드 값을 사용한다는 의미이다. 한마디로 kedcd필드를 pk필드에 복사하겠다는 의미와 같다.
- drop : 이벤트를 완전히 삭제한다.
filter {
if [loglevel] == "debug" {
drop { }
}
}
loglevel 필드의 값이 debug인 경우 이벤트를 삭제하겠다는 것을 의미한다.
- clone : 이벤트의 복사본을 만들고 필드를 추가하거나 제거할 수 있다.
- geoip : IP주소의 지리적 위치에 대한 정보를 추가한다.
LogStash의 filter 플러그인 역시 굉장히 많으므로 필요에 따라 공식문서 등을 참고하여 활용하면 된다.
📌 Outputs ( 출력 )
output은 LogStash 파이프라인의 마지막 단계이다. 간단하게 생각하면 LogStash에서 전처리한 데이터를 어디에 전송해줄지 결정해주는 영역이라고 볼 수 있다. 대표적으로 ElasticSearch를 자주 사용한다.

- elasticsearch : Elasticsearch로 데이터를 전송한다. 효율적이고 쉽게 쿼리 형태로 데이터를 전송할 수 있는 방법이다.
output {
elasticsearch {
hosts => ["http://IP주소:포트번호"]
index => "ElasticSearch에 저장될 인덱스명"
user => "사용자 이름"
document_id => "문서ID"
password => "ElasticSearch에 연결할 때 사용할 암호"
}
}
-
file : 디스크의 파일에 이벤트 데이터를 작성해준다.
-
graphite : 데이터를 저장하고 그래프로 표시하는 용도로 사용되는 오픈소스 graphite로 데이터를 전송한다.
✅ LogStash의 Config
Input, Filter, Output에 대한 설정은 conf 파일에 작성해서 저장하면 된다. 이벤트 마다 다른 conf파일을 작성하면 되고, example.conf 와 같은 형태로 만들면 된다.
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}
📌 LogStash Conf파일 예제
input {
# 파일에서 로그 데이터를 읽어오는 설정
file {
path => "/var/log/nginx/access.log" # 읽어올 로그 파일 경로
start_position => "beginning" # 파일을 처음부터 읽기
sincedb_path => "/dev/null" # sincedb 파일을 사용하지 않음
}
# JDBC를 사용하여 데이터베이스에서 데이터를 읽어오는 설정
jdbc {
jdbc_driver_library => "/path/to/mysql-connector-java.jar" # JDBC 드라이버 라이브러리 경로
jdbc_driver_class => "com.mysql.jdbc.Driver" # 사용할 JDBC 드라이버 클래스
jdbc_connection_string => "jdbc:mysql://localhost:3306/database_name" # 데이터베이스 연결 문자열
jdbc_user => "username" # 데이터베이스 사용자 이름
jdbc_password => "password" # 데이터베이스 비밀번호
statement => "SELECT * FROM table_name" # 실행할 쿼리문
jdbc_paging_enabled => true # 페이징 활성화
jdbc_page_size => 1000 # 페이지 크기
}
# Kafka로부터 데이터를 수신하는 설정
kafka {
bootstrap_servers => "localhost:9092" # Kafka 브로커의 호스트 및 포트
topics => ["topic_name"] # 구독할 토픽 이름
group_id => "logstash_consumer_group" # 컨슈머 그룹 ID
codec => json # 데이터 형식 (JSON 등)
}
}
filter {
# 파일 및 JDBC input에 대한 공통 필터링 및 구문 분석
if [input_type] == "file" or [input_type] == "jdbc" {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} %{NUMBER:bytes}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
# 파일 input에 대한 추가 필터
if [input_type] == "file" {
mutate {
add_field => { "source_type" => "nginx_access_log" }
}
}
# JDBC input에 대한 추가 필터
if [input_type] == "jdbc" {
mutate {
add_field => { "source_type" => "database_table" }
}
}
# Kafka input에 대한 추가 필터
if [input_type] == "kafka" {
mutate {
add_field => { "source_type" => "kafka_topic" }
}
}
# 필요에 따라 추가적인 필터링 및 필드 조작 작업을 수행할 수 있습니다.
# 예제: 특정 필드가 특정 값과 일치할 때 이벤트를 삭제하는 필터
if [status] == "404" {
drop {}
}
}
output {
# Elasticsearch에 데이터를 전송하는 설정
elasticsearch {
hosts => ["localhost:9200"] # Elasticsearch 호스트 및 포트
index => "%{source_type}" # Elasticsearch에 인덱싱될 이름을 source_type 필드 값으로 동적 설정
}
# stdout으로 데이터를 출력하는 설정 (디버깅 용도)
stdout {}
}
댓글남기기