

[ELK] Kibana(키바나)란? 개념부터 주요 기능, 설치, KQL까지 총정리
업데이트:
빅데이터 아키텍처에서 시각화는 굉장히 중요하다. 예를 들어, 내 웹사이트를 방문한 사람들의 방문 시간대를 알고싶다면 엘라스틱서치를 활용해 어렵지 않게 요일과 시간대별로 사용자수를 알아낼 수 있을 것이다. 그러나 이렇게 얻은 결과를 단순 테이블 형태로 파악한다면 눈에 잘 들어오지 않을 것이다. 이 때문에 우리는 많은 양의 비정형적인 데이터를 보고서나 대시보드 형태로 시각화 하는 과정이 필요하다.
우리는 비츠와 로그스태시를 이용해 수집하고 가공한 데이터를 엘라스틱 서치에 저장하고 이를 Kibana를 통해서 시각화 할 것이다.
📚 ELK 스택 시리즈
- ElasticSearch(엘라스틱서치)란?
- LogStash(로그스태시)란?
- Kibana(키바나)란? ← 현재 글
- ELK 스택이란?
✅ Kibana란?
Kibana는 Elastic Stack의 중요한 구성 요소 중 하나로, 데이터 시각화 및 분석 도구이다. Elasticsearch에서 저장된 데이터를 쉽게 시각화 하고 탐색할 수 있는 웹 인터페이스를 제공한다. Kibana는 사용자가 Elasticsearch에 쿼리를 실행하고, 결과를 다양한 형태로 시각화 하여 분석할 수 있도록 도와준다. Kibana의 기능은 크게 세가지 정도로 분류될 수 있다.
-
데이터 분석과 시각화 툴 오픈소스 기반의 데이터 탐색 및 시각화 도구 제공
-
엘라스틱 관리 보안, 스냅샷, 인덱스 관리, 개발자 도구 등 제공
-
엘라스틱 중앙 허브 모니터링을 비롯해 엘라스틱 솔루션을 탐색하기 위한 포털
✅ Kibana 사용 이유
그렇다면 Kibana를 언제, 왜 사용해야 할까? 만약 Elasticsearch를 검색엔진으로 사용하면서 Kibana를 사용하지 않는다면 통계 페이지나 데이터 처리를 위해 WAS를 직접 구성하고, amCharts, c3 등의 차트 라이브러리를 이용하여 UI 코드를 작성해야 할 것이다. 번거로운 작업이지만 하려면 할 수 있다.
그러나 Kibana를 사용하면 쉽고 간단하고 빠르게 데이터 시각화를 완성할 수 있다. 또한 Kibana는 오픈소스이기 때문에 접근성도 좋다. 때문에 Elasticsearch의 실시간 데이터 시각화를 위해서는 Kibana는 거의 필수라고 볼 수 있다.
정리하면 Kibana를 사용하는 핵심 이유는 다음과 같다.
- 별도 개발 없이 드래그 앤 드롭만으로 시각화 가능
- 실시간 모니터링 - 자동 새로고침으로 시스템 상태를 실시간 확인
- Elasticsearch와 네이티브 통합 - 추가 설정 없이 바로 연동
- 오픈소스 - 무료로 사용 가능하며 커뮤니티가 활발
✅ Kibana 설치 및 접속
Kibana는 Elasticsearch가 먼저 설치되어 있어야 동작한다. 설치 과정은 다음과 같다.
📌 설치 방법
1) 직접 설치 (Linux/Mac)
# Kibana 다운로드 (버전은 Elasticsearch와 동일하게 맞춰야 함)
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.x.x-linux-x86_64.tar.gz
tar -xzf kibana-8.x.x-linux-x86_64.tar.gz
cd kibana-8.x.x/
# 실행
./bin/kibana
2) Docker로 설치
docker run -d --name kibana \
--net elastic \
-p 5601:5601 \
docker.elastic.co/kibana/kibana:8.x.x
3) 접속
설치 후 브라우저에서 http://localhost:5601로 접속하면 Kibana 웹 UI를 사용할 수 있다.
📌 kibana.yml 주요 설정
# Kibana 서버 포트 (기본값: 5601)
server.port: 5601
# Kibana 서버 호스트
server.host: "0.0.0.0"
# 연결할 Elasticsearch 주소
elasticsearch.hosts: ["http://localhost:9200"]
# Elasticsearch 인증 정보 (필요 시)
elasticsearch.username: "kibana_system"
elasticsearch.password: "your_password"
⚠️ Kibana 버전은 반드시 Elasticsearch 버전과 동일해야 한다. 버전이 다르면 호환성 문제가 발생할 수 있다.
✅ Kibana의 시각화 주요 기능
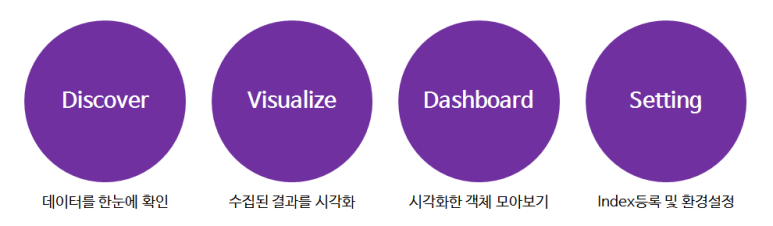
Kibana 시각화에는 여러 주요 기능이 있다. Discover, Lens, Visualize, Dashboard, Canvas, Maps 등이 있는데 각각에 대해 알아보도록 하자.
📌 Discover
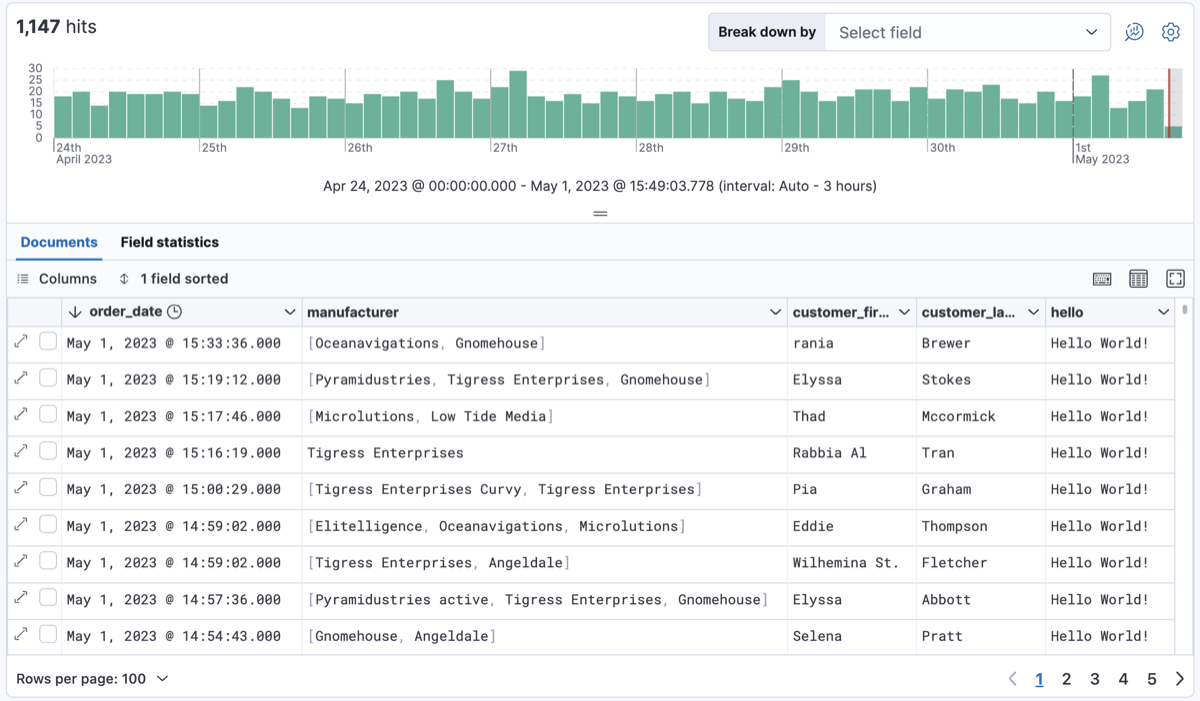
Discover는 데이터를 확인하고 탐색하기 위한 용도로 사용된다. 문서/이벤트/도큐먼트/로그의 시간에 따른 발생량을 히스토그램으로 보여주기도 하고 데이터 구조나 필드 타입 등을 간단히 확인할 수도 있다.
주요 활용 방법은 다음과 같다.
- 시간 범위 필터링 - 특정 기간의 데이터만 조회
- 필드별 필터 - 특정 필드 값으로 데이터 필터링
- KQL 쿼리 - Kibana Query Language로 상세 검색 (아래에서 자세히 설명)
📌 Lens
Lens는 Kibana 7.5부터 도입된 시각화 도구로, 드래그 앤 드롭 방식으로 누구나 쉽게 차트를 만들 수 있다. 기존 Visualize보다 직관적이며, Kibana에서 가장 권장하는 시각화 방법이다.
Lens의 주요 특징은 다음과 같다.
- 드래그 앤 드롭 - 필드를 끌어다 놓기만 하면 자동으로 최적의 차트 타입을 추천
- 차트 타입 자동 추천 - 데이터 특성에 맞는 시각화 방식을 제안
- 실시간 미리보기 - 설정을 변경할 때마다 즉시 결과 확인 가능
- 수식 지원 - 필드 간 연산이나 커스텀 메트릭 생성 가능
💡 Kibana 8.x 이상에서는 Visualize 대신 Lens 사용을 권장한다. Lens가 더 직관적이고 기능도 지속적으로 확장되고 있다.
📌 Visualize
Visualize 메뉴는 엘라스틱 서치에 저장된 데이터를 그래프나 표, 지도 등 다양한 타입으로 보여주는 역할을 한다. 라인, 바, 파이 차트부터 맵, 시계열 비주얼 빌더, 태그 클라우드 등 다양한 시각화 타입을 지원한다. 가장 효과적으로 데이터를 보여줄 수 있는 타입을 선택하면 된다. 이때 시각화는 엘라스틱 서치의 집계를 통해 그래프를 그린다.
⚠️ 메트릭 집계 : 평균/최소/최대 같은 수량을 계산한다.
⚠️ 버킷 집계 : 특정 기준에 맞춰 데이터를 분리한다. 서브 버킷을 생성할 수 있다.
⚠️ 파이프라인 집계 : 집계 결과를 입력으로 받아 다시 집계를 한다. 부모/형제 집계 유형이 있다.
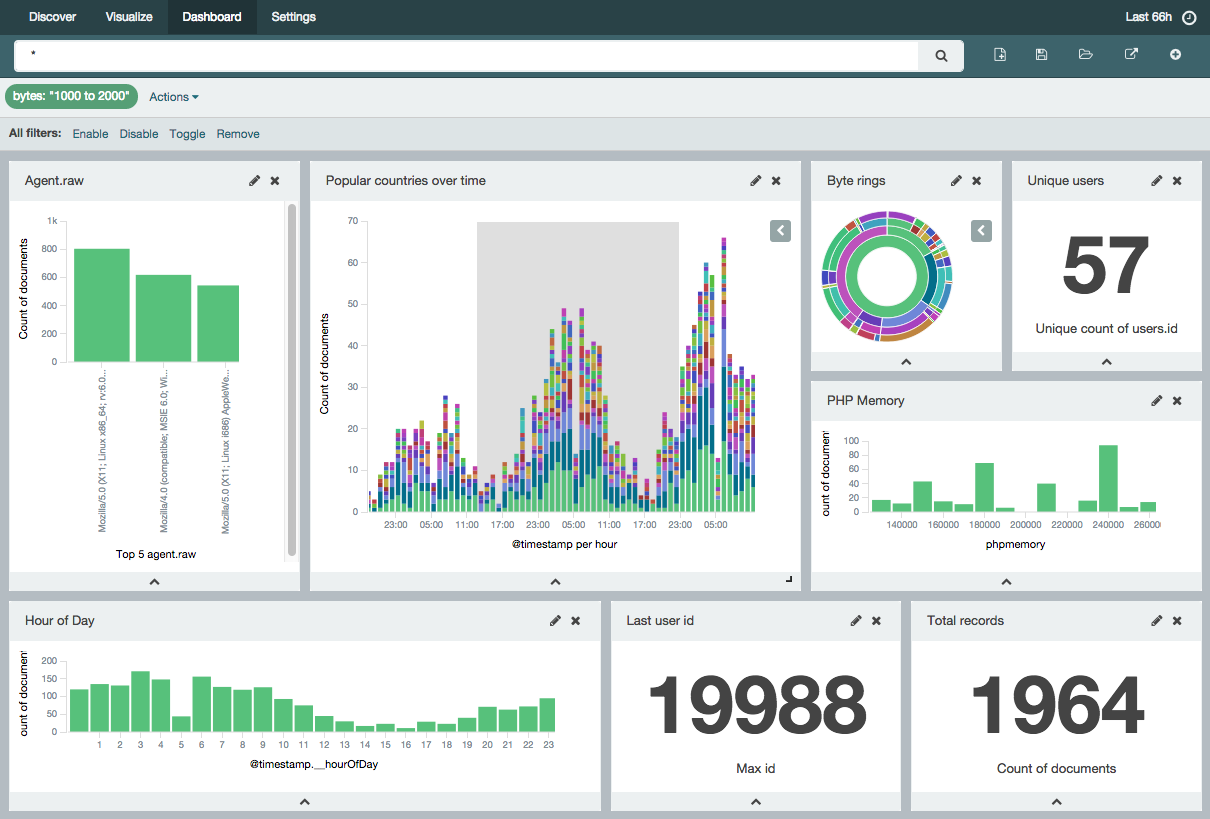
📌 Dashboard
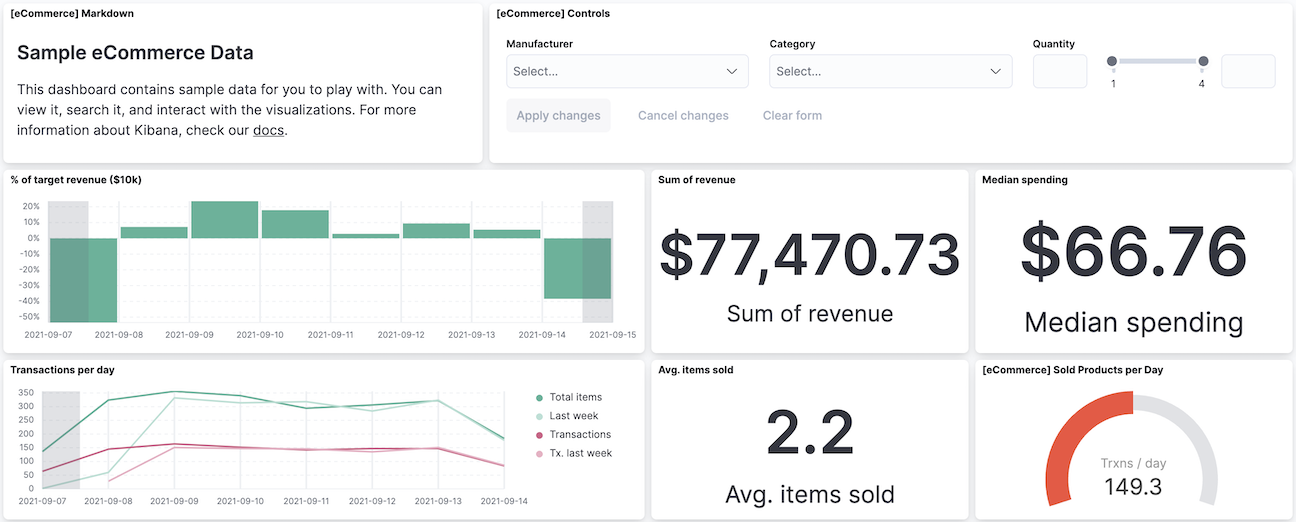
대시보드는 시각화 타입들을 한 페이지에 모아 볼 수 있는 기능으로, 한 화면에서 다양한 관점으로 데이터를 보면서 분석할 수 있다. 또한 자동 새로고침 기능을 이용해 대시보드를 통해 시스템을 실시간으로 모니터링 할 수 있다. 따로 기술적으로 학습해야 하거나 어려운 내용은 없다.
📌 Canvas
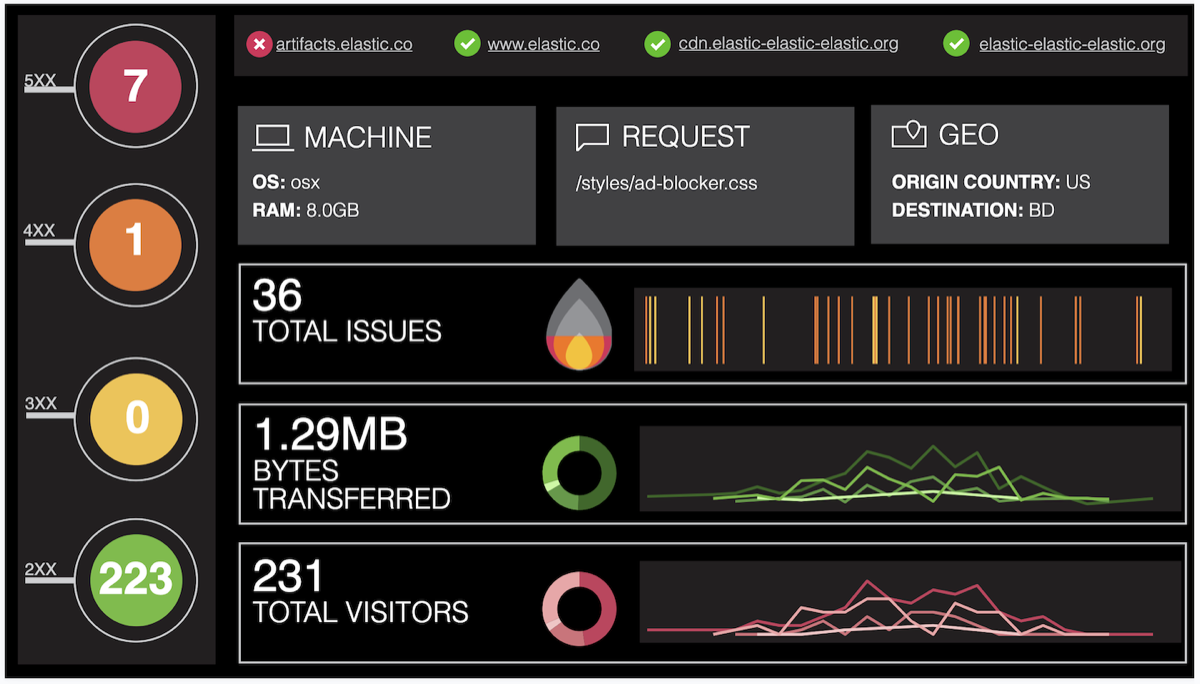
캔버스는 인포그래픽 형태로 데이터를 프레젠테이션할 수 있게 해주는 툴이다. 일종의 파워포인트 처럼 화면을 편집하고 보여줄수 있다고 생각하면 된다. Kibana의 Dashboard가 아주 좋은 시각화 모듈을 제공하지만, 뭔가 정형화된 느낌이 들어 본인만의 방식으로 시각화 자료를 만들고 싶다면 Canvas를 사용하면 된다.
💡 Kibana 8.x 이후 Canvas 기능은 점차 Dashboard에 통합되는 추세이다. 새로운 프로젝트에서는 Dashboard + Lens 조합을 우선 고려하는 것이 좋다.
📌 Maps
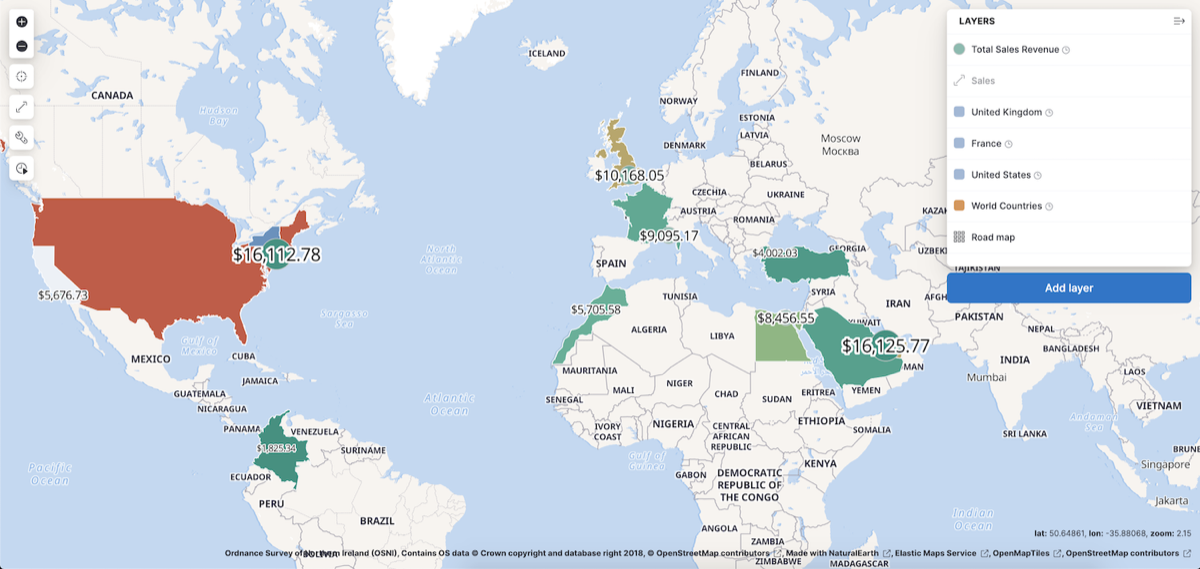
Maps는 위치정보가 포함된 데이터를 지도에 올려 시각화 할 수 있고, 멀티 레이어 가능을 통해 다양한 형태의 지도를 레이어한 화면에서 볼 수 있다.
✅ KQL (Kibana Query Language)
KQL은 Kibana에서 데이터를 검색할 때 사용하는 쿼리 언어이다. Discover, Dashboard 등에서 상단 검색창에 KQL 문법으로 쿼리를 입력하면 원하는 데이터를 필터링할 수 있다.
📌 KQL 기본 문법
1) 필드 값 검색
status: "error"
response_code: 404
2) 와일드카드 검색
message: "timeout*"
host.name: server-*
3) 논리 연산자 (AND, OR, NOT)
status: "error" AND response_code: 500
level: "warn" OR level: "error"
NOT status: "success"
4) 범위 검색
response_time > 1000
bytes >= 5000 AND bytes <= 10000
5) 존재 여부 확인
error.message: *
⚠️ KQL은 Lucene 쿼리와 다르다. Kibana 검색창 좌측에서 KQL 모드가 활성화되어 있는지 확인하자. Lucene 모드에서는 문법이 다르게 동작한다.
✅ 실무 활용 예시
Kibana는 다양한 실무 환경에서 활용된다. 대표적인 사례를 살펴보자.
📌 서버 로그 모니터링
- Filebeat → Logstash → Elasticsearch → Kibana Dashboard
- 실시간 에러 로그 추적, 응답시간 모니터링
- 특정 시간대 에러 급증 시 알림 설정 가능
📌 비즈니스 데이터 분석
- 사용자 행동 패턴 분석 (방문 시간대, 페이지뷰 등)
- 매출/주문 데이터 실시간 대시보드
- A/B 테스트 결과 시각화
📌 보안 모니터링 (SIEM)
- 네트워크 트래픽 이상 탐지
- 로그인 실패 패턴 분석
- Elastic Security 솔루션과 연동하여 보안 위협 대시보드 구성
댓글남기기